Have you ever wondered how Netflix predicts your next favorite movie or how your phone unlocks with a single look? Data and a lot of processing power are not enough. Everything is happening because of the ALGORITHMS.
Algorithm Machine Learning are the basic elements of systems in the field of algorithms. Without them, there’s no prediction, no automation, no artificial intelligence. The brains that work in the background make sure robots learn, adapt, and make decisions.
Personalized shopping, self-driving cars, and disease diagnosis are just a few of the everyday technologies secretly powered by algorithm machine learning. In this blog, we’ll break down why these mathematical engines are so important and how they’ve become the smallest unit of modern AI.
What Are Machine Learning Algorithms?
Let’s say you run a little coffee shop in your neighborhood. Every day, your sales differ in price. Some days you’re packed, other days it’s quiet. You start to think:
“Is there a way to predict how many cups of coffee I’ll sell tomorrow?”
You’ve got data:
- Daily sales numbers
- Weather conditions
- Weekday vs. weekend
Now, instead of guessing, you turn to algorithm machine learning. It acts as your personal digital assistant that doesn’t just record numbers, but it actually learns from the data.
This algorithm looks at your past data and finds patterns you probably wouldn’t even notice, like:
- Sales spike on rainy mornings
- Weekends bring in 20% more traffic
- Local art festivals double your espresso orders
Once it understands these trends, it can say something like:
“Hey, based on tomorrow’s weather forecast and event calendar, you’re likely to sell around 180 cups.”
So, what’s the point?
A machine learning algorithm is basically a smart system that learns from data, spots patterns, and makes decisions without being told how to do it every time.
And this isn’t just for coffee shops.
- It’s how Spotify figures out your next favorite song?
- How Google Maps predicts traffic?
- How doctors use the MyChart app to forecast health risks?
In Simple Terms:
A machine learning algorithm is like a smart assistant who studies all your past experiences, finds patterns you might miss, and helps you make better decisions in the future, without being exactly told how to do it.
Types of Machine Learning Paradigms
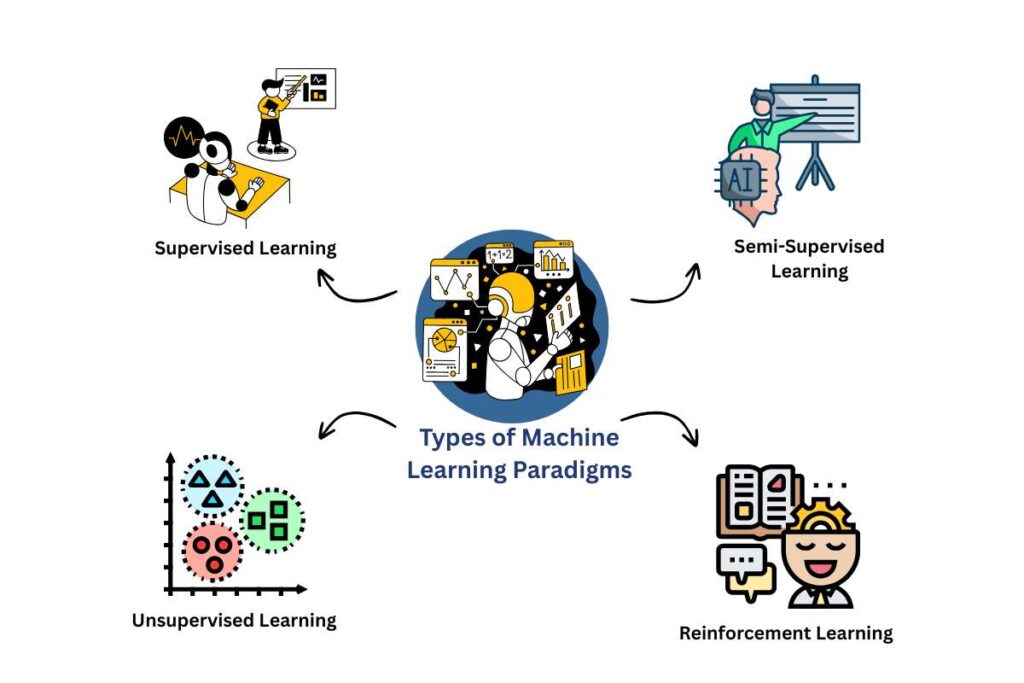
Just like humans can learn in different ways by being taught, figuring things out on their own, or learning through experience, machines also have four main ways of learning.
1. Supervised Learning
Think of it like learning with a teacher. The algorithm is trained on labeled data, which means it already knows the right answers. It learns by example and uses that to predict outcomes for new data.
Example: Imagine teaching a machine to recognize fruits. You show lots of pictures labeled “apple” or “banana.” It learns the patterns and then can guess correctly when shown a new fruit.
Used for:
- Email spam detection
- Predicting house prices
- Sentiment analysis (positive/negative reviews)
2. Unsupervised Learning
Think of it like learning without a teacher. The data has no labels, so the algorithm tries to find hidden patterns or groupings on its own.
Example: Give a machine a bunch of customer data with no labels. It might figure out that some customers buy often, while others don’t, and group them into segments.
Used for:
- Customer division
- Market-based analysis
- Grouping similar products or behaviors
3. Semi-Supervised Learning
It involves taking a little help from the teacher, but mostly figuring it out alone. Uses a small amount of labeled data and a large amount of unlabeled data. It’s a mix of supervised and unsupervised learning.
Example: If you have 1000 medical images but only 100 are labeled “cancer” or “no cancer,” semi-supervised learning can learn patterns from both labeled and unlabeled data to improve predictions.
Used for:
- Medical diagnosis
- Speech recognition
- Language translation
4. Reinforcement Learning
It includes learning by trial and error, just like playing a video game. The machine interacts with an environment. It gets rewards or penalties for its actions and learns the best way to achieve a goal.
Example: When you start training a robot to walk. At first, it fell a lot. But over time, it learns which movements earn rewards, like standing straight, and avoids actions that lead to failure.
Used for:
- Self-driving cars
- Game-playing AI (like AlphaGo)
- Robotics and automation
Top Algorithms Machine Learning Types (With Examples)

1. Linear Regression
| Developed In | 1805 (formalized) |
| Use cases | House pricing, sales forecasting. |
| What it does | Predicts numerical values from input data using a straight-line relationship. |
Zillow uses linear regression, which is one of the top algorithm machine learning language to estimate home prices based on data like square footage, number of bedrooms, location, and neighborhood trends. The algorithm draws a best-fit line that shows how each factor impacts price, helping buyers and sellers make informed decisions.
2. Logistic Regression
| Developed In | 1958 |
| Use cases | Disease diagnosis, email spam filtering. |
| What it does | Predicts categorical outcomes (yes/no) with probabilities. |
Gmail uses logistic regression to decide whether an incoming email is spam or not. It looks at patterns like certain words in the subject line, email metadata, and user behavior. Based on training from millions of emails, it predicts a binary outcome: spam or not spam.
3. Decision Tree
| Developed In | 1986 |
| Use cases | Loan approvals, customer churn. |
| What it does | Splits data step-by-step based on features, resembling flowchart logic. |
Uber applies decision tree logic to determine fare pricing. Inputs like distance, demand, traffic, time of day, and weather are fed into the model. Based on a sequence of decisions, it determines the most reasonable price for your trip in real-time.
4. Random Forest
| Developed In | 2001 |
| Use cases | Fraud detection, credit scoring. |
| What it does | Builds a crowd of decision trees and averages their results. |
In fraud detection, banks use Random Forest models to analyze transaction data. It takes into account transaction time, amount, location, and frequency. By building multiple decision trees, it can flag suspicious transactions that deviate from usual patterns with high accuracy.
5. Naive Bayes
| Developed In | 1700s (Bayes’ Theorem), applied in ML since 1950s |
| Use cases | Document classification, sentiment analysis. |
| What it does | Applies probability to determine the class of a data instance. |
Twitter uses Naive Bayes to filter spammy or harmful tweets. It also classifies tweet sentiment (positive, negative, or neutral) by analyzing word frequency. Since the model assumes words are independent, it’s super fast, which is ideal for real-time decisions.
6. K-Nearest Neighbors (KNN)
| Developed In | 1951 |
| Use cases | Recommendation systems, pattern recognition. |
| What it does | Classifies new items based on the labels of their neighbors. |
Netflix uses KNN to recommend shows and movies. When you watch a particular show, it looks for other users who watched and liked the same thing. It then suggests titles that users enjoyed as your “nearest neighbors.” The same goes for Spotify suggesting similar songs.
7. Support Vector Machine (SVM)
| Developed In | 1992 |
| Use cases | Image classification, text categorization. |
| What it does | Finds the boundary that best separates two classes. |
Facebook applies SVM in facial recognition. When you upload a photo, the system detects faces and compares them with your friends’ profile pictures. SVM separates faces with fine boundaries based on features like the distance between eyes or nose shape to tag the right person.
8. K-Means Clustering
| Developed In | 1967 |
| Use cases | Customer segmentation, data compression. |
| What it does | Organizes data into groups based on similarity. |
Amazon uses K-Means to segment customers based on their shopping behavior. For example, it might create clusters like: “frequent shoppers,” “deal hunters,” or “occasional buyers.” This allows personalized marketing, sending better product recommendations and offers.
9. Gradient Boosting
| Developed In | GBM: 1999, XGBoost: 2014 |
| Use cases | Predictive analytics, risk modeling. |
| What it does | Builds successive models that correct previous errors. |
In data science competitions on Kaggle, Gradient Boosting (especially XGBoost) consistently ranks as the most accurate model. Insurance companies use it to predict things like claim amounts or policy risks, fine-tuning each decision step-by-step by fixing earlier prediction errors.
10. AdaBoost (Adaptive Boosting)
| Developed In | 1996 |
| Use cases | Facial recognition, binary classification. |
| What it does | Focuses on difficult-to-classify data points iteratively. |
Adobe Sensei uses AdaBoost in tools like Photoshop to enhance image recognition. It focuses more on hard-to-detect objects, like distinguishing a shadow from an object, by strengthening weaker predictions made in earlier steps. It’s also used in facial feature detection.
Deep Learning vs Traditional Algorithm Machine Learning
| Parameter | Traditional Machine Learning | Deep Learning |
| Definition | Uses algorithms to learn patterns from data with manual input | A subset of ML that uses neural networks to automatically learn patterns |
| Feature Engineering | Manual: You select which features are important | Automatic: Learns features from raw data on its own |
| Type of Data | Works best on structured data (tables, spreadsheets) | Excels at unstructured data (images, audio, video, text) |
| Data Requirement | Performs well with smaller datasets | Needs large volumes of data to be effective |
| Training Time | Generally faster to train | Usually slower, due to multiple layers and huge datasets |
| Understandability | Easy to understand how predictions are made | Hard to understand (acts as a black box) |
| Scalability | Less scalable for very large datasets | Highly scalable with big data |
| Industry Use Cases | Banking, retail analytics, and healthcare reports | Self-driving cars, voice assistants, medical imaging, and NLP |
How to Choose the Right Algorithm Machine Learning?
| Choose Traditional ML if… | Choose Deep Learning if… |
| Your dataset is small or medium-sized | You have a large dataset (e.g., millions of records/images) |
| Your data is structured and well-organized | Your data is unstructured (text, images, speech, etc.) |
| You need fast results and clear explanations | You aim for high accuracy and can sacrifice transparency |
| You have limited computing resources (e.g., no GPUs) | You can access powerful hardware (GPUs or cloud computing) |
Real-World Use Cases of Algorithm Machine Learning
Uber’s dynamic (surge) pricing adjusts fares in real-time based on demand, location, availability, traffic, and more.
A 2025 report from Oxford studied 1.5 million UK rides and confirmed that after implementing dynamic pricing in 2023:
- Uber’s commission rose from around 25% to ~29%, sometimes over 50%.
- Drivers’ hourly earnings dropped from £22 to ~£19 before costs.
A Columbia Business School study on US rides highlighted fare drops for drivers and higher rider costs; Uber’s take rate increased from 32%.
How Uber Uses Algorithm Machine Learning?
Uber uses algorithm machine learning to power its dynamic pricing, ride matching, and ETA predictions.
- Surge pricing adjusts fares in real time using models like decision trees and neural networks, based on demand, traffic, and location.
- Oxford University (2025) found Uber’s algorithm increased fares by up to 50% in high-demand zones while reducing driver earnings by 15% (Source).
- It also uses ML to match riders with nearby drivers and optimize routes, improving efficiency for both sides.
Source :- A Case Study of an ML Architecture – Uber
Future Trends in Algorithm Machine Learning

Several innovative advances are influencing how algorithms create, learn, and scale as we look to the future of algorithm machine learning:
1. AutoML (Automated Machine Learning)
AutoML tools allow non-experts to build powerful models without coding or manual tuning. Platforms like Google AutoML and Microsoft Azure ML automate feature engineering, model selection, and hyperparameter tuning, cutting development time drastically.
2. Federated Learning
Rather than sending data to the cloud, federated learning trains models locally on devices, preserving privacy while enabling real-time updates. It’s particularly useful in sectors like finance and healthcare where sensitive data must remain on-device.
3. Explainable AI (XAI)
With algorithms increasingly making critical decisions, the demand for transparency is growing. Explainable AI aims to shed light on black-box models like deep neural networks, helping businesses and regulators understand why decisions were made.
4. Quantum Machine Learning
Quantum computing introduces exponential power to ML. Quantum lead algorithms like QAOA and VQE are already being tested for optimization and pattern recognition, offering potential breakthroughs in fields like pharmaceuticals and logistics.
5. Edge AI
Instead of relying on cloud-based servers, Edge AI allows ML models to run on local devices like smartphones, drones, and IoT sensors. This ensures lower latency, better privacy, and real-time decision-making, perfect for industries like agriculture, autonomous vehicles, and manufacturing.
Conclusion
Algorithm Machine Learning is quietly reshaping our everyday lives. Whether it’s Spotify curating your next playlist or Uber optimizing fare prices in real-time, these algorithms are more than just code; they’re decision-making engines built to learn and adapt.
Understanding the types of machine learning paradigms, their real-world applications, and the right algorithm for the job empowers businesses and professionals to innovate confidently. And as trends like AutoML, Edge AI, and quantum learning take off, the future holds limitless potential.
If you want to stay ahead in AI, now’s the time to embrace the power of algorithm machine learning, because the systems that learn today will lead tomorrow.
Also Read :- Cyberpro Magazine




